Open LLMs on Your Platform
Posted on 26th March 2024, last updated 28th March 2024.

In a previous blog post we considered commercial LLMs. While such commercial products are typically the state of the art, there are also many drawbacks. They cost money to use, almost always a lot more than their true running costs. They are always run on the provider's servers. Their architecture, model parameters, and training data is typically undisclosed. And most importantly, data security considerations may often prohibit you from using such models. This is because you'll have to share your sensitive data on the platform of a commercial provider and getting assurances for the security of your data can be difficult.
In this blog post we'll cover open LLMs which provide an alternative to their commercial counterparts. We'll define what we mean by an open LLM and distinguish between a foundation model and an instruction tuned model. There are several "levels" of "being open" and several variations on licenses and the data available for such LLMs. We'll discuss these levels. We'll then discuss several model running platforms which you can use to run such open LLMs locally, e.g., Ollama. Finally we'll survey the key models that are currently available. The models we consider are,
- DBRX from Databricks
- Meta's Llama 2 models (7B, 13B, 70B)
- Mistral's Mistral 7B and Mixtral 8x7B
- Google's Gemma
- Falcon (7B, 40B, 180B)
- Qwen 1.5
- Stable LM Zephyr 3B
- Microsoft's Phi-2
- Cohere's Aya
- X's (Twitter's) Grok-1
We should also note that these are all base models. Since they are open, some of them have been fine-tuned to yield other models which specialize in certain things. For example, on Hugging Face you can find tens of thousands of models that have been fine-tuned based on the above base models. Such fine-tuning and sharing of the model is generally not possible with commercial LLMs because they are not open.
What exactly do we mean by "open"?
There isn't one single answer, rather there are a few variations. In the most lax sense, one would expect that the parameters (weights) of an open model are available online and can be downloaded and run on your computing infrastructure. With this one would also expect that the model architecture and specification is open and known, such as through supporting source code. All open models share this characteristic and all the commercial models do not. But one can also expect that the training data which was used to train the model is available. This is the case with some open models but not with others. Finally, there is a question on the type of license. Some open models can be used in your commercial operations without constraints whereas with others there are restrictions. As we discuss the above open models we'll describe all of these attributes for each model.
Foundation models vs. instruction-tuned models
When we consider an LLM, we can generally describe it as either being a foundation model or an instruction-tuned model. In a nutshell, a foundation model is trained on large bodies of text and can complete text efficiently yet does not know how to answer questions and perform tasks or follow instructions well. An instruction tuned model is a foundation model that has been further refined to be able to perform tasks, such as to answer questions, to summarize text, and to be safe in its responses. So basically the process of creating a model is to first create a foundation model and then to modify it to be instruction tuned.
This distinction between foundation and instruction-tuned versions is also relevant to commercial models, yet the form of the commercial models available to the public are always instruction tuned. In contrast, with open models we often (but not always) see the model vendor providing both a foundation version and an instruction tuned version. As we discuss the above open models we'll describe which forms are available per model.
Model size and system requirements
With commercial LLMs we often don't even know the size of the LLM, but with open LLMs we know the size of the model exactly. Small models have under 3 billion parameters and larger ones can have hundreds of billions of parameters. On a laptop you can expect to run models with under 10 billion parameters, yet performance may be slow. Stay tuned for a future blog post where we survey hardware requirements for different models.
How to run open models
Supporting software for running Large Language Models (LLMs) locally, such as Ollama and LMStudio, offers users the ability to deploy AI technologies directly on their own infrastructure. Ollama is a command line tool that prioritizes data privacy and adaptability, catering to a wide range of applications from content generation to data analysis. LMStudio, on the other hand, targets developers and researchers with its user-friendly interface for model experimentation and deployment, promoting extensive customization and innovation. Both platforms are pivotal in making AI available for everyone, facilitating the integration of sophisticated LLM functionalities into various environments without reliance on external cloud services. Note that Ollama essentially works on all platforms while LMStudio is slightly more restricted as for Macs it requires the Mac to be M1/M2/M3.
Instead of installing an open model locally or on your infrastructure you can use online cloud services that already manage and host this installation for you. One of the most impressive options is Groq which have their own special chips that run LLMs at blazing speed. Other options include together.ai and Amazon Bedrock.
Fine-tuned derived models on Huggingface
The good thing about open models is that anyone from the community may take them and further improve them. This is called fine-tuning. The most popular place to find fine-tuned models is Hugging Face. At the time of writing, there are almost 70,000 text-generation models available on Hugging Face. Some of these are just experiments run by enthusiasts, while others are variations of open models that are fine-tuned for specific tasks, and have already been very useful in practice. Just as an example, one popular derived model is Hermes 2 which is derived from Mistral 7B.
Details about the models
Let us now describe the open models we will be looking at.
DBRX from Databricks
DBRX is an open LLM fresh off the press, released by Databricks just yesterday (as of writing). It's a huge mixture of experts model (a similar architecture to Mixtral 8x7B) with 132B parameters in total, one of the largest open models. The claimed performance is very competitive, even with commercial solutions, but the jury is still out on how it will place in real-world performance.

Meta's Llama 2 (7B, 13B, 70B)
Llama 2 is a collection of models ranging from 7 to 70 billion parameters, optimized for dialogue and various tasks, demonstrating superior performance on benchmarks and in human evaluations for helpfulness and safety. It is fair to say that Meta advanced the the open source LLM model arena with their choice of making Llama open sourced.

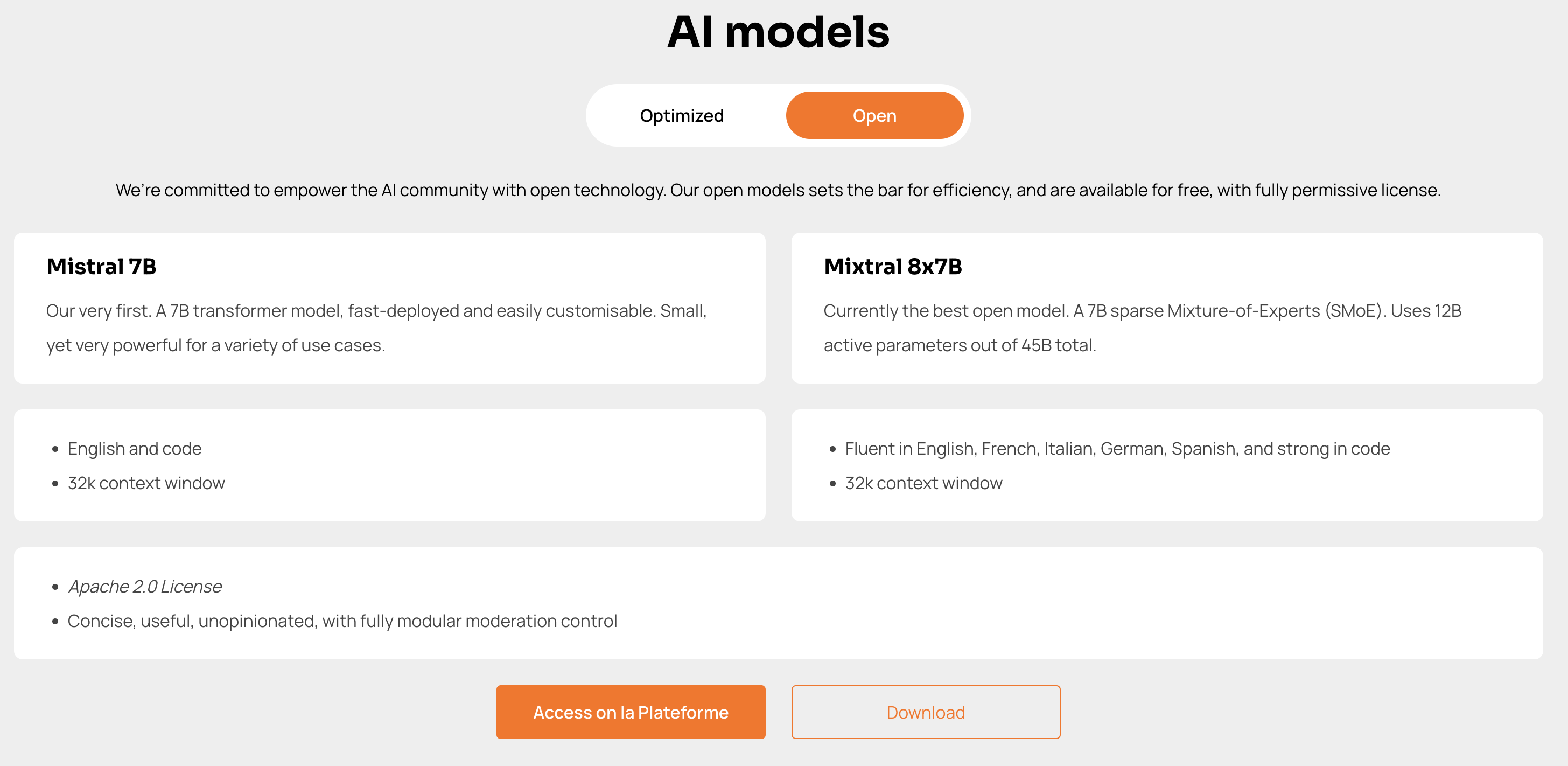
Mistral's Mistral 7B and Mixtral 8x7B
Mistral 7B is recognized for its excellence in performance and efficiency across various benchmarks, notably surpassing Llama 2 13B and showing prowess in code, mathematics, and reasoning tasks. Mixtral 8x7B, offered alongside Mistral 7B stands out as a high-quality, sparse Mixture-of-Experts model ideal for tasks such as text summarization, question answering, text classification, completion, and code generation, optimized for low latency and high throughput.
Google's Gemma
Gemma, by Google, introduces state-of-the-art, lightweight open models excelling in math and coding, outperforming similar-sized models like LLaMA 2 and Mistral-7B. Gemma models come with comprehensive safety measures and a toolkit for developing safe AI applications.
Falcon 7B, 40B, 180B
The Falcon AI models offer cutting-edge performance, with the Falcon-180B achieving top marks on the Open LLM Leaderboard due to its massive scale and comprehensive training dataset.

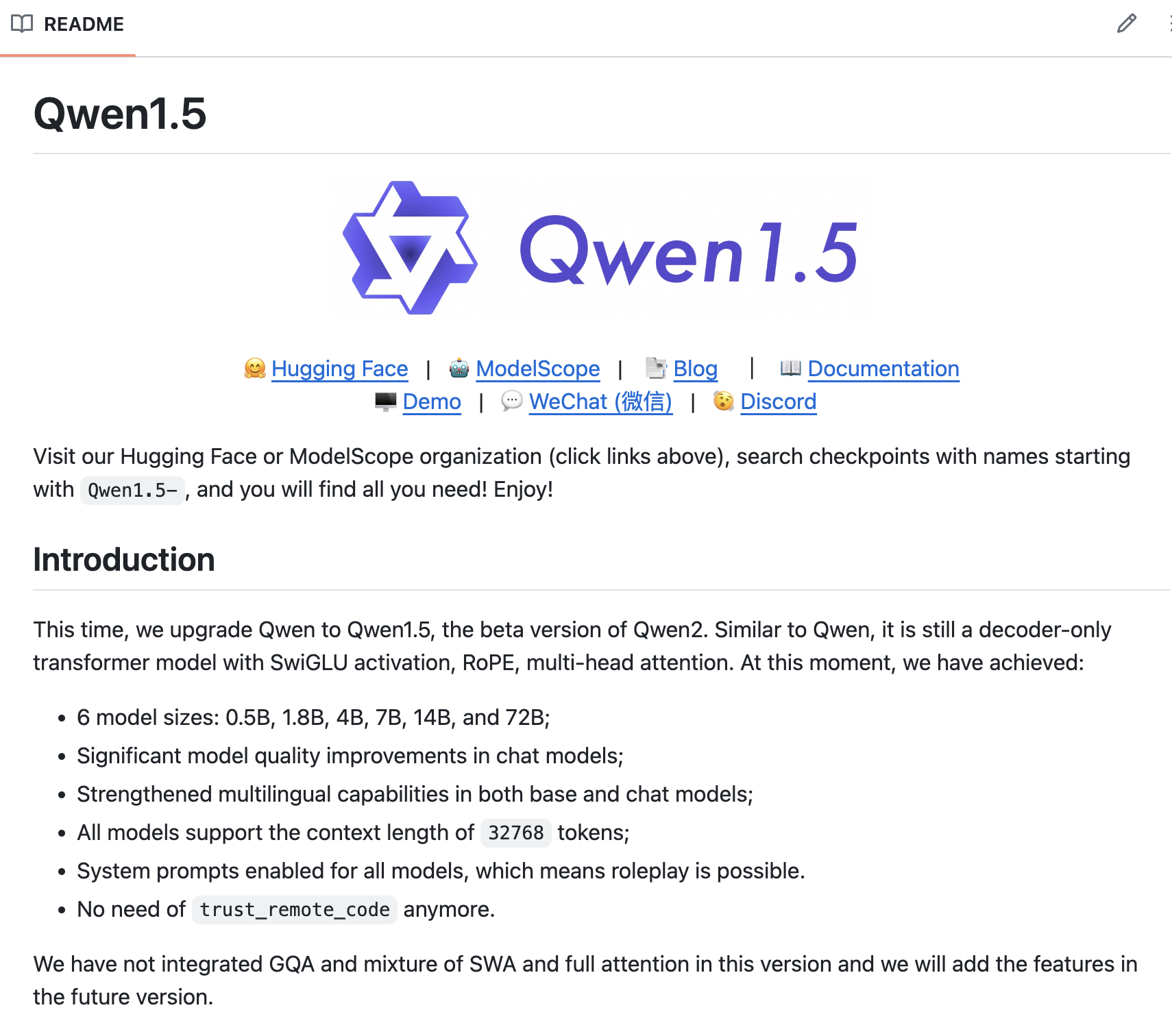
Qwen1.5
For developers and researchers, Qwen1.5 offers enhanced multilingual support, covering 12 languages across various dimensions such as exams, understanding, translation, and math. This makes it a robust tool for applications requiring high-quality multilingual content generation.
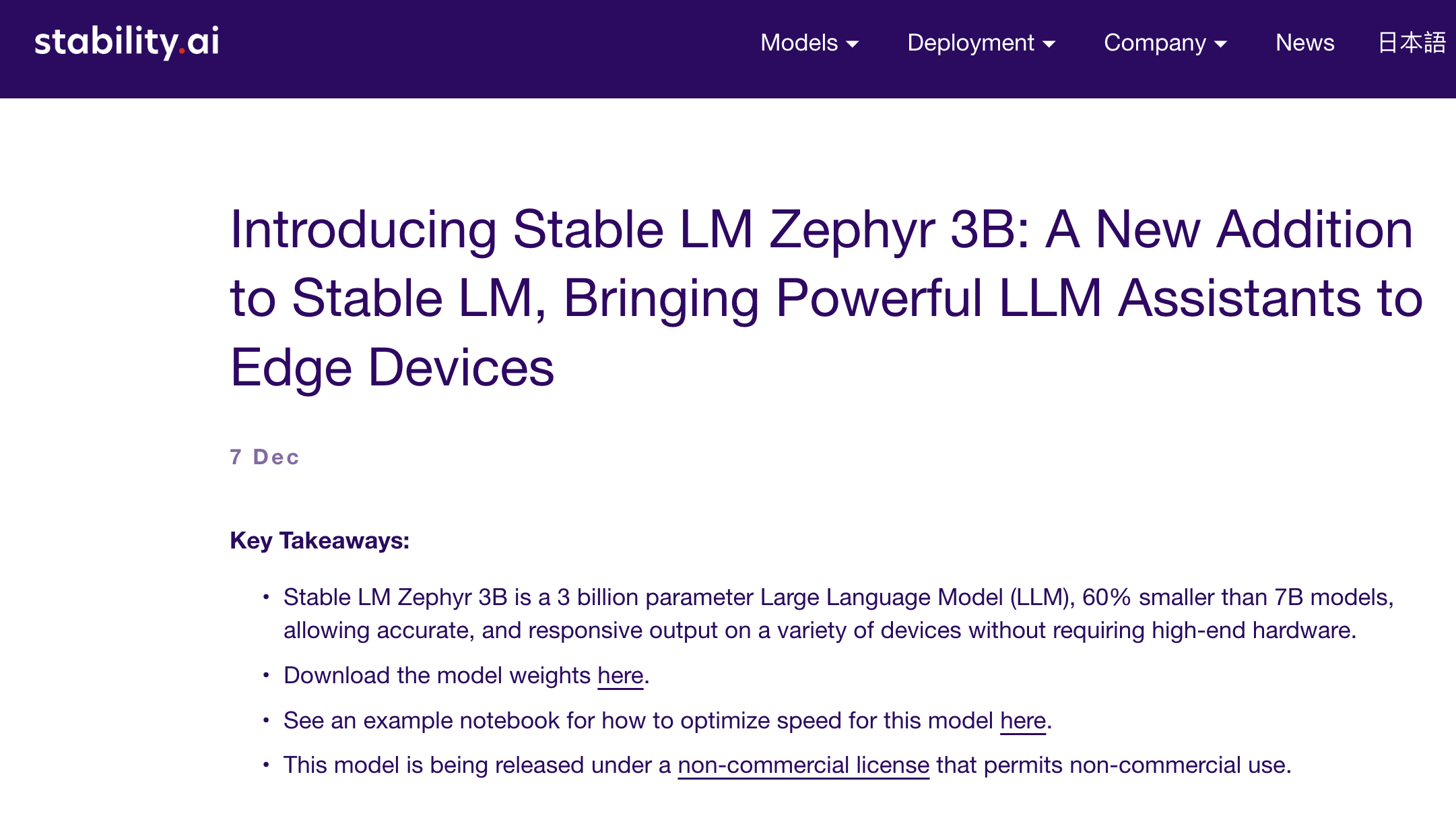
Stable LM Zephyr 3B
StableLM Zephyr 3B, by Stability AI, is a compact 3 billion parameter model designed for efficient operation on edge devices, capable of instruction-following and question-answering tasks. Despite its smaller size, it performs comparably to larger models, focusing on human alignment through supervised fine-tuning and preference tuning.
Microsoft's Phi-2
Phi-2 is a compact yet powerful 2.7 billion-parameter language model by Microsoft that outperforms larger models in reasoning and language understanding. Trained on high-quality data, it was developed efficiently over 14 days using 96 A100 GPUs. Ideal for AI research, Phi-2 excels without needing reinforcement learning from human feedback.
Cohere's Aya
Cohere's Aya is a groundbreaking multilingual language model that understands 101 languages, focusing on inclusivity for underrepresented communities. It outperforms similar models on various tasks and introduces extensive evaluation suites for a broad linguistic range.
X's (Twitter's) Grok-1
Grok-1 is a 314 billion parameter Mixture-of-Experts model unveiled by xAI, designed to improve accessibility and foster innovation in AI. It excels in efficiency and adaptability, utilizing a fraction of its parameters for specific tasks. Open-sourced under the Apache 2.0 license, Grok-1 encourages collaboration within the AI community.

Where to from here?

In this post, we've explored the world of open Large Language Models (LLMs), highlighting their distinct advantages over commercial alternatives. We've delved into what defines an open LLM, the crucial difference between foundation models and instruction-tuned models, and how these variations impact the technology's application. Additionally, we've surveyed several key open models available today, discussing their features, capabilities, and licensing details. This discussion not only sheds light on the technical aspects of these models but also underscores the broader implications for data privacy, accessibility, and innovation in the field of AI. As the AI race continues, it's clear that open models play a pivotal role in democratizing AI technology, offering more flexibility, transparency, and opportunities for customization and advancement.
© 2018 – 2026 Accumulation Point Pty Ltd. All rights reserved.